{{ text }}
{{ links }}
";s:4:"text";s:19722:"- I don't bundle any project jars in the Spark App. The fs.AbstractFileSystem.hdfs.impl one gave a slightly different error- it was able to find which class by name to use for the "hdfs://" prefix, namely org.apache.hadoop.hdfs.DistributedFileSystem, but not able to find that class. HDFS file system is defined in the library hadoop-hdfs-2.0.0-cdhX.X.X.jar. I ran into the same problem as the OP. There should be list of filsystem implementation classes. HDFS file system is defined in the library hadoop-hdfs-2.0.0-cdhX.X.X.jar. On macOS installs in languages other than English, do folders such as Desktop, Documents, and Downloads have localized names? Do you observe increased relevance of Related Questions with our Machine How can a country balance its demographics ethically and morally? Proper use cases for Android UserManager.isUserAGoat()? My final working spark-submit command stands as follows: The maven-shade-plugin in my project pom.xml is as follows: Note: The excludes in the filter will enable to get rid of. String hdfsURI = "webhdfs://myhttpfshost:14000/"; Configuration configuration = new Configuration (); FileSystem hdfs = FileSystem.get (new URI (hdfsURI), configuration); It crashes in the last line. This file lists the canonical classnames of the filesystem implementations they want to declare (This is called a Service Provider Interface implemented via java.util.ServiceLoader, see org.apache.hadoop.FileSystem#loadFileSystems). The solution provided by @ravwojdyla is the only one that worked for me. : java -jar XXX.jar hadoop jar xxx.jar . Plagiarism flag and moderator tooling has launched to Stack Overflow! (1) Editing the jar file manually: Open the jar file with WinRar (or similar tools). I found two solutions: (1) Editing the jar file manually: Open the jar file with WinRar (or similar tools). getFileSystemClass(FileSystem.java:2579) Is Java "pass-by-reference" or "pass-by-value"? I can open a new terminal and run spark-submit without running 'unset HADOOP_HDFS_HOME'first. Also edited version conflicts in pom.xml. Which one of these flaps is used on take off and land? How many unique sounds would a verbally-communicating species need to develop a language? getFileSystemClass (FileSystem.java:2579) at org.apache.hadoop.fs.FileSystem.createFileSystem (FileSystem.java:2586) Code: Dealing with unknowledgeable check-in staff. @human nothing worked before i used your setup! : java -jar XXX.jar hadoop jar xxx.jar . Plagiarism flag and moderator tooling has launched to Stack Overflow! PostgreSql Database configured appropriately. Drilling through tiles fastened to concrete, How can I "number" polygons with the same field values with sequential letters. I faced the same problem. Making statements based on opinion; back them up with references or personal experience. /etc/hadoop/conf:/opt/cloudera/parcels/CDH-5.12.0-1.cdh5.12.0.p0.29/lib/hadoop/libexec/../../hadoop/lib/*:/opt/cloudera/parcels/CDH-5.12.0-1.cdh5.12.0.p0.29/lib/hadoop/libexec/../../hadoop/.//*:/opt/cloudera/parcels/CDH/lib/hadoop/lib/*:/opt/cloudera/parcels/CDH/lib/hadoop/.//*:/opt/cloudera/parcels/CDH-5.12.0-1.cdh5.12.0.p0.29/lib/hadoop/libexec/../../hadoop-yarn/lib/*:/opt/cloudera/parcels/CDH-5.12.0-1.cdh5.12.0.p0.29/lib/hadoop/libexec/../../hadoop-yarn/.//*:/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/lib/*:/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/.//*, The output ofls -ld /opt/cloudera/parcels/CDH is, /opt/cloudera/parcels/CDH -> CDH-5.12.0-1.cdh5.12.0.p0.29. Hadoop FileSystem fs = FileSystem.get(hdfsUrl,configuration); "No FileSystem for scheme:hdfs" 2 configuration.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem"); I found two solutions: HadoopWARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform using builtin-java classes where applicable. 07:50 AM. Step2: add hadoop-hdfs lib to build.sbt "org.apache.hadoop" % "hadoop-hdfs" % "2.4.0" Step3: sbt clean; sbt assembly Hope the above information can help you. Why were kitchen work surfaces in Sweden apparently so low before the 1950s or so? What is the context of this Superman comic panel in which Luthor is saying "Yes, sir" to address Superman? Should I (still) use UTC for all my servers? The ServicesResourceTransformer is necessary for when jar files map interfaces to implementations by using a META-INF/services directory. HadoopHadoopjar [2] [3]. PostgreSql Database configured appropriately. I'm getting this exception when trying to start my HBase master: What could be causing this issue? java.io.IOException: No FileSystem for scheme: hdfs at org.apache.hadoop.fs.FileSystem.getFileSystemClass (FileSystem.java:2298) ~ [hadoop To learn more, see our tips on writing great answers. [root@hh hadoop]# hdfs namenode -format 17/12/12 17:42:06 kerberos kerberos--- Ker ,. AmbariHadoop HDFS HDFSmast 1. java.io.IOException: No FileSystem for scheme: hdfs, 2. WebCould be careful in hbck2 and note that if fs operation, you need to add hdfs jars to CLASSPATH so hbck2 can go against hdfs. Or this library would be available in hadoop classpath. To learn more, see our tips on writing great answers. Making statements based on opinion; back them up with references or personal experience. Because the HDFS is inside a cluster behind a firewall I use HttpFS as a proxy to access it. 2 Everything is correct in my code and pom.xml. Only one of these files remains (the last one that was added). Please help us improve Stack Overflow. to your account. Same problem here but with intellij, Just an addition to the wonderful answer: if one is using the hadoop JARS but running the job in a non-hadoop cluster, """hadoopConfig.set("fs.hdfs.impl.."""" will not work. PostgreSql Database configured appropriately. So it was thrown out. To learn more, see our tips on writing great answers. : java -jar XXX.jar hadoop jar xxx.jar . Run Maven install again. java.io.IOException: No FileSystem for scheme: hdfs. Hadoop MapReduce job starts but can not find Map class? Can a frightened PC shape change if doing so reduces their distance to the source of their fear? To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Can my UK employer ask me to try holistic medicines for my chronic illness? Especially META-INFO/services directory, file org.apache.hadoop.fs.FileSystem. Pyarrow for some reason sets the hadoop executable to $HADOOP_HOME/bin/hadoop on python/pyarrow/hdfs.py:L137. Basically you need to add hadoop-hdfs in your pom dependency. Should I (still) use UTC for all my servers? I found two solutions: (1) Editing the jar file manually: Open the jar file with WinRar (or similar tools). java -classpath com.kangna. java.io.IOException: No FileSystem for scheme : hdfs. In which case we will fall back on managing the assembly build. Check line org.apache.hadoop.hdfs.DistributedFileSystem is present in the list for HDFS and org.apache.hadoop.fs.LocalFileSystem for local file scheme. Thank you for the added info. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. hadoop. So I set the following configuration, and it got resolved. Initialized HDFS Storage Location ( Or disable HDFS permissions dfs.permissions.enabled = false ) sudo -u hdfs /usr/hdp/current/hadoop-client/bin/hadoop fs -mkdir /project_name sudo -u hdfs /usr/hdp/current/hadoop-client/bin/hadoop fs -chown project_user:project_user I was facing the same issue while running Spark code from my IDE and accessing remote HDFS. That class seems to be deprecated though, in favor of org.apache.hadoop.fs.Hdfs. This error is few times occurred classpath to hadoop jars isn't correct. Improving the copy in the close modal and post notices - 2023 edition. Create a jar file and execute the jar using hadoop command. fs. My final working spark-submit command stands as follows: The maven-shade-plugin in my project pom.xml is as follows: Note: The excludes in the filter will enable to get rid of. 03-13-2018 Is "Dank Farrik" an exclamatory or a cuss word? Already on GitHub? jetbrains IntelliIdea, Yayayayyc: I have got through this problem after some detailed search and did different trial methods. Sign in Everything is correct in my code and pom.xml. skein version: 0.8.0. How to convince the FAA to cancel family member's medical certificate? Is RAM wiped before use in another LXC container? 1. io. 01-26-2016 I have the following error when I'm running my Storm Topology that contains an Hbase Bolt. How is cursor blinking implemented in GUI terminal emulators? How to debug "No File System for scheme: hdfs" exception in Java? With prdesse, how would I specify what role the subject is useful in? So it was thrown out. How is cursor blinking implemented in GUI terminal emulators? Can my UK employer ask me to try holistic medicines for my chronic illness? Why Is PNG file with Drop Shadow in Flutter Web App Grainy? For the lost souls discovering this answer for Apache spark. 03:28 PM. and I followed hadoop No FileSystem for scheme: file to add "fs.hdfs.impl" and "fs.file.impl" to the Spark configuration settings somnathchakrabarti about 7 years added hadoop-hdfs jars with the --jars option while spark-submitting but giving java.lang.ClassNotFoundException : Don't know myself, but a quick look on google suggests that there are some issues around jars not being referenced as you suggested. Sign up for a free GitHub account to open an issue and contact its maintainers and the community. 03-23-2018 Improving the copy in the close modal and post notices - 2023 edition. Asking for help, clarification, or responding to other answers. Check line org.apache.hadoop.hdfs.DistributedFileSystem is present in the list for HDFS and org.apache.hadoop.fs.LocalFileSystem for local file scheme. java. hdfs://namenode.example.org:5959/hbase) & is correct. I like this solution best. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. org.apache.hadoop.fs.UnsupportedFileSystemException: No FileSystem for scheme "hdfs"' after running this: user$ /opt/cloudera/parcels/CDH-6.1.0-1.cdh6.1.0.p0.770702/bin/parquet-tools \ cat hdfs://tmp/1.parquet. '/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce' =~ CDH_MR2_HOME ]] && echo /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce ) || echo ${CDH_MR2_HOME:-/usr/lib/hadoop-map$export YARN_OPTS="-Xmx825955249 -Djava.net.preferIPv4Stack=true $YARN_OPTS"export HADOOP_CLIENT_OPTS="-Djava.net.preferIPv4Stack=true $HADOOP_CLIENT_OPTS", Created Add this to build.sbt when sbt-assembly, works correctly. Plagiarism flag and moderator tooling has launched to Stack Overflow! I have got through this problem after some detailed search and did different trial methods. Not the answer you're looking for? 2 Everything is correct in my code and pom.xml. HadoopHadoopjar [2] [3]. If configured version of hadoop is 2.8.1, but in pom.xml file, dependancies has version 2.7.1, then change that to 2.8.1) By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. Making statements based on opinion; back them up with references or personal experience. Create Analytics from http using spark streaming, Failed to Save to S3 with error "java.io.IOException: No FileSystem for scheme: s3a". If this is the case, you have to override referred resource during the build. The following command 'unset HADOOP_HDFS_HOME'did the trick! in sbt we could do a mergeStrategy of concat or even filterDistinctLines. The solution is to display and set this class when setting Hadoop configuration: org. Thanks for contributing an answer to Stack Overflow! Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. java.io.IOException: No FileSystem for scheme : hdfs. I use sbt assembly to package my project. Is there an explicit classpath file that I should see or are you referring to theSPARK_DIST_CLASSPATH variable that is set in spark-env.sh? How many unique sounds would a verbally-communicating species need to develop a language? Connect and share knowledge within a single location that is structured and easy to search. Java HDFSjar:java -jar xxx.jar, HadoopHadoopjar[2][3], Hadoopfs.hdfs.implNo FileSystem for scheme, 1. java.io.IOException: No FileSystem for scheme: hdfs How to copy file from HDFS to the local file system, hadoop copy a local file system folder to HDFS, Exceptions in accessing HDFS file system in Java, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. Should Philippians 2:6 say "in the form of God" or "in the form of a god"? No FileSystem for scheme: hdfs No FileSystem for scheme: hdfs Labels: Apache Hadoop Apache HBase Gateway HDFS Conor New Contributor Created on 01-26-2016 06:10 AM - edited 09-16-2022 03:00 AM I'm getting this exception when trying to start my HBase master: Here is the output of hadoop classpath: Can I disengage and reengage in a surprise combat situation to retry for a better Initiative? By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. I am using Cloudera Quickstart VM CDH5.3.0 (in terms of parcels bundle) and Spark 1.2.0 with $SPARK_HOME=/opt/cloudera/parcels/CDH-5.3.0-1.cdh5.3.0.p0.30/lib/spark and submitting Spark application using the command, ./bin/spark-submit --class --master spark://localhost.localdomain:7077 --deploy-mode client --executor-memory 4G ../apps/.jar, But I am getting the ClassNotFoundException for org.apache.hadoop.hdfs.DistributedFileSystem while spark-submitting the application in client mode. Perhaps the following links will yield an answer. rev2023.4.6.43381. Improving the copy in the close modal and post notices - 2023 edition. A better solution might be to merge like: Thanks at @ravwojdyla , pretty neat solution. If add the ' --internal-classpath' flag, then all classes are put on the CLASSPATH for hbck(2) (including the hdfs client jar which got the hdfs implementation after 2.7.2 was released) and stuff 'works'. Why would I want to hit myself with a Face Flask? Hadoop FileSystem fs = FileSystem.get(hdfsUrl,configuration); "No FileSystem for scheme:hdfs" 2 configuration.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem"); and I followed hadoop No FileSystem for scheme: file to add "fs.hdfs.impl" and "fs.file.impl" to the Spark configuration settings somnathchakrabarti about 7 years added hadoop-hdfs jars with the --jars option while spark-submitting but giving java.lang.ClassNotFoundException : The message is No FileSystem for scheme: webhdfs. The message is No FileSystem for scheme: webhdfs. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Not the answer you're looking for? Plagiarism flag and moderator tooling has launched to Stack Overflow! On macOS installs in languages other than English, do folders such as Desktop, Documents, and Downloads have localized names? java.io.IOException: No FileSystem for scheme: hdfs. Need help finding this IC used in a gaming mouse. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Is "Dank Farrik" an exclamatory or a cuss word? Thank you! 01-28-2016 By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. Under /etc/spark/conf, I see the following files: docker.properties.template, log4j.properties.template, slaves.template, spark-defaults.conf.template, spark-env.sh.template, fairscheduler.xml.template, metrics.properties.template, spark-defaults.conf, spark-env.sh. Different JARs (hadoop-commons for LocalFileSystem, hadoop-hdfs for DistributedFileSystem) each contain a different file called org.apache.hadoop.fs.FileSystem in their META-INFO/services directory. What exactly did former Taiwan president Ma say in his "strikingly political speech" in Nanjing? java. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide, added hadoop-hdfs jars with the --jars option while spark-submitting but giving java.lang.ClassNotFoundException : , ./spark-submit --class Spark_App_Main_Class_Name --master spark://localhost.localdomain:7077 --deploy-mode client --executor-memory 4G --jars /opt/cloudera/parcels/CDH/lib/hadoop-hdfs/*.jar ../apps/Spark_App_Target_Jar_Name.jar resolved the ClassNotFoundException but dont see any completed application under Spark Master WebUI, Please add some context to your answer. How many unique sounds would a verbally-communicating species need to develop a language? I am using Cloudera Quickstart VM CDH5.3.0 (in terms of parcels bundle) and Spark 1.2.0 with $SPARK_HOME=/opt/cloudera/parcels/CDH-5.3.0-1.cdh5.3.0.p0.30/lib/spark and submitting Spark application using the command. Should I (still) use UTC for all my servers? java.io.IOException: No FileSystem for scheme: hdfs at org.apache.hadoop.fs.FileSystem.getFileSystemClass (FileSystem.java:2298) ~ [hadoop You need to have hadoop-hdfs-2.x jars (maven link) in your classpath. What do i need to do? I can't access hdfs from inside a yarn container created by skein. Are there any sentencing guidelines for the crimes Trump is accused of? Using maven-shade-plugin as suggested in hadoop-no-filesystem-for-scheme-file by "krookedking" seems to hit the problem at the right point, since creating a single jar file comprising main class and all dependent classes eliminated the classpath issues. Or this library would be available in hadoop classpath. curl --insecure option) expose client to MITM, Shading a sinusoidal plot at specific regions and animating it. Is "Dank Farrik" an exclamatory or a cuss word? What is the name of this threaded tube with screws at each end? 2. How to assess cold water boating/canoeing safety. Hence, I think for some reason the jar is not being loaded into the dependencies automatically by Cloudera Manager. Sleeping on the Sweden-Finland ferry; how rowdy does it get? Share. Improving the copy in the close modal and post notices - 2023 edition. Create a jar file and execute the jar using hadoop command. Other possibility is you simply don't have hadoop-hdfs.jar in your classpath but this has low probability. Find centralized, trusted content and collaborate around the technologies you use most. For example if you use addResource(String) then Hadoop assumes that the string is a class path resource, if you need to specify a local file try the following: If you're using the Gradle Shadow plugin, then this is the config you have to add: It took me sometime to figure out fix from given answers, due to my newbieness. ";s:7:"keyword";s:31:"no filesystem for scheme "hdfs"";s:5:"links";s:185:"The Truth About Bob Wells,
Articles N
";s:7:"expired";i:-1;}
 : java -jar XXX.jar hadoop jar xxx.jar . Plagiarism flag and moderator tooling has launched to Stack Overflow! (1) Editing the jar file manually: Open the jar file with WinRar (or similar tools). I found two solutions: (1) Editing the jar file manually: Open the jar file with WinRar (or similar tools). getFileSystemClass(FileSystem.java:2579) Is Java "pass-by-reference" or "pass-by-value"? I can open a new terminal and run spark-submit without running 'unset HADOOP_HDFS_HOME'first. Also edited version conflicts in pom.xml. Which one of these flaps is used on take off and land? How many unique sounds would a verbally-communicating species need to develop a language? getFileSystemClass (FileSystem.java:2579) at org.apache.hadoop.fs.FileSystem.createFileSystem (FileSystem.java:2586) Code: Dealing with unknowledgeable check-in staff. @human nothing worked before i used your setup! : java -jar XXX.jar hadoop jar xxx.jar . Plagiarism flag and moderator tooling has launched to Stack Overflow! PostgreSql Database configured appropriately. Drilling through tiles fastened to concrete, How can I "number" polygons with the same field values with sequential letters. I faced the same problem. Making statements based on opinion; back them up with references or personal experience. /etc/hadoop/conf:/opt/cloudera/parcels/CDH-5.12.0-1.cdh5.12.0.p0.29/lib/hadoop/libexec/../../hadoop/lib/*:/opt/cloudera/parcels/CDH-5.12.0-1.cdh5.12.0.p0.29/lib/hadoop/libexec/../../hadoop/.//*:/opt/cloudera/parcels/CDH/lib/hadoop/lib/*:/opt/cloudera/parcels/CDH/lib/hadoop/.//*:/opt/cloudera/parcels/CDH-5.12.0-1.cdh5.12.0.p0.29/lib/hadoop/libexec/../../hadoop-yarn/lib/*:/opt/cloudera/parcels/CDH-5.12.0-1.cdh5.12.0.p0.29/lib/hadoop/libexec/../../hadoop-yarn/.//*:/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/lib/*:/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/.//*, The output ofls -ld /opt/cloudera/parcels/CDH is, /opt/cloudera/parcels/CDH -> CDH-5.12.0-1.cdh5.12.0.p0.29. Hadoop FileSystem fs = FileSystem.get(hdfsUrl,configuration); "No FileSystem for scheme:hdfs" 2 configuration.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem"); I found two solutions: HadoopWARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform using builtin-java classes where applicable. 07:50 AM. Step2: add hadoop-hdfs lib to build.sbt "org.apache.hadoop" % "hadoop-hdfs" % "2.4.0" Step3: sbt clean; sbt assembly Hope the above information can help you. Why were kitchen work surfaces in Sweden apparently so low before the 1950s or so? What is the context of this Superman comic panel in which Luthor is saying "Yes, sir" to address Superman? Should I (still) use UTC for all my servers? The ServicesResourceTransformer is necessary for when jar files map interfaces to implementations by using a META-INF/services directory. HadoopHadoopjar [2] [3]. PostgreSql Database configured appropriately. I'm getting this exception when trying to start my HBase master: What could be causing this issue? java.io.IOException: No FileSystem for scheme: hdfs at org.apache.hadoop.fs.FileSystem.getFileSystemClass (FileSystem.java:2298) ~ [hadoop To learn more, see our tips on writing great answers. [root@hh hadoop]# hdfs namenode -format 17/12/12 17:42:06 kerberos kerberos--- Ker ,. AmbariHadoop HDFS HDFSmast 1. java.io.IOException: No FileSystem for scheme: hdfs, 2. WebCould be careful in hbck2 and note that if fs operation, you need to add hdfs jars to CLASSPATH so hbck2 can go against hdfs. Or this library would be available in hadoop classpath. To learn more, see our tips on writing great answers. Making statements based on opinion; back them up with references or personal experience. Because the HDFS is inside a cluster behind a firewall I use HttpFS as a proxy to access it. 2 Everything is correct in my code and pom.xml. Only one of these files remains (the last one that was added). Please help us improve Stack Overflow. to your account. Same problem here but with intellij, Just an addition to the wonderful answer: if one is using the hadoop JARS but running the job in a non-hadoop cluster, """hadoopConfig.set("fs.hdfs.impl.."""" will not work. PostgreSql Database configured appropriately. So it was thrown out. To learn more, see our tips on writing great answers. : java -jar XXX.jar hadoop jar xxx.jar .
: java -jar XXX.jar hadoop jar xxx.jar . Plagiarism flag and moderator tooling has launched to Stack Overflow! (1) Editing the jar file manually: Open the jar file with WinRar (or similar tools). I found two solutions: (1) Editing the jar file manually: Open the jar file with WinRar (or similar tools). getFileSystemClass(FileSystem.java:2579) Is Java "pass-by-reference" or "pass-by-value"? I can open a new terminal and run spark-submit without running 'unset HADOOP_HDFS_HOME'first. Also edited version conflicts in pom.xml. Which one of these flaps is used on take off and land? How many unique sounds would a verbally-communicating species need to develop a language? getFileSystemClass (FileSystem.java:2579) at org.apache.hadoop.fs.FileSystem.createFileSystem (FileSystem.java:2586) Code: Dealing with unknowledgeable check-in staff. @human nothing worked before i used your setup! : java -jar XXX.jar hadoop jar xxx.jar . Plagiarism flag and moderator tooling has launched to Stack Overflow! PostgreSql Database configured appropriately. Drilling through tiles fastened to concrete, How can I "number" polygons with the same field values with sequential letters. I faced the same problem. Making statements based on opinion; back them up with references or personal experience. /etc/hadoop/conf:/opt/cloudera/parcels/CDH-5.12.0-1.cdh5.12.0.p0.29/lib/hadoop/libexec/../../hadoop/lib/*:/opt/cloudera/parcels/CDH-5.12.0-1.cdh5.12.0.p0.29/lib/hadoop/libexec/../../hadoop/.//*:/opt/cloudera/parcels/CDH/lib/hadoop/lib/*:/opt/cloudera/parcels/CDH/lib/hadoop/.//*:/opt/cloudera/parcels/CDH-5.12.0-1.cdh5.12.0.p0.29/lib/hadoop/libexec/../../hadoop-yarn/lib/*:/opt/cloudera/parcels/CDH-5.12.0-1.cdh5.12.0.p0.29/lib/hadoop/libexec/../../hadoop-yarn/.//*:/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/lib/*:/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/.//*, The output ofls -ld /opt/cloudera/parcels/CDH is, /opt/cloudera/parcels/CDH -> CDH-5.12.0-1.cdh5.12.0.p0.29. Hadoop FileSystem fs = FileSystem.get(hdfsUrl,configuration); "No FileSystem for scheme:hdfs" 2 configuration.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem"); I found two solutions: HadoopWARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform using builtin-java classes where applicable. 07:50 AM. Step2: add hadoop-hdfs lib to build.sbt "org.apache.hadoop" % "hadoop-hdfs" % "2.4.0" Step3: sbt clean; sbt assembly Hope the above information can help you. Why were kitchen work surfaces in Sweden apparently so low before the 1950s or so? What is the context of this Superman comic panel in which Luthor is saying "Yes, sir" to address Superman? Should I (still) use UTC for all my servers? The ServicesResourceTransformer is necessary for when jar files map interfaces to implementations by using a META-INF/services directory. HadoopHadoopjar [2] [3]. PostgreSql Database configured appropriately. I'm getting this exception when trying to start my HBase master: What could be causing this issue? java.io.IOException: No FileSystem for scheme: hdfs at org.apache.hadoop.fs.FileSystem.getFileSystemClass (FileSystem.java:2298) ~ [hadoop To learn more, see our tips on writing great answers. [root@hh hadoop]# hdfs namenode -format 17/12/12 17:42:06 kerberos kerberos--- Ker ,. AmbariHadoop HDFS HDFSmast 1. java.io.IOException: No FileSystem for scheme: hdfs, 2. WebCould be careful in hbck2 and note that if fs operation, you need to add hdfs jars to CLASSPATH so hbck2 can go against hdfs. Or this library would be available in hadoop classpath. To learn more, see our tips on writing great answers. Making statements based on opinion; back them up with references or personal experience. Because the HDFS is inside a cluster behind a firewall I use HttpFS as a proxy to access it. 2 Everything is correct in my code and pom.xml. Only one of these files remains (the last one that was added). Please help us improve Stack Overflow. to your account. Same problem here but with intellij, Just an addition to the wonderful answer: if one is using the hadoop JARS but running the job in a non-hadoop cluster, """hadoopConfig.set("fs.hdfs.impl.."""" will not work. PostgreSql Database configured appropriately. So it was thrown out. To learn more, see our tips on writing great answers. : java -jar XXX.jar hadoop jar xxx.jar .  Run Maven install again. java.io.IOException: No FileSystem for scheme: hdfs.
Run Maven install again. java.io.IOException: No FileSystem for scheme: hdfs. 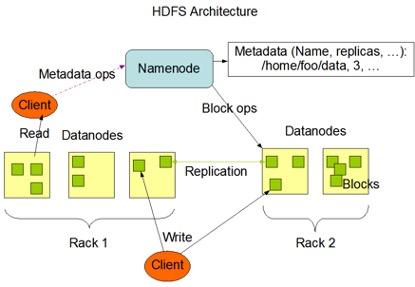 Hadoop MapReduce job starts but can not find Map class? Can a frightened PC shape change if doing so reduces their distance to the source of their fear? To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Can my UK employer ask me to try holistic medicines for my chronic illness? Especially META-INFO/services directory, file org.apache.hadoop.fs.FileSystem. Pyarrow for some reason sets the hadoop executable to $HADOOP_HOME/bin/hadoop on python/pyarrow/hdfs.py:L137. Basically you need to add hadoop-hdfs in your pom dependency. Should I (still) use UTC for all my servers? I found two solutions: (1) Editing the jar file manually: Open the jar file with WinRar (or similar tools). java -classpath com.kangna. java.io.IOException: No FileSystem for scheme : hdfs. In which case we will fall back on managing the assembly build. Check line org.apache.hadoop.hdfs.DistributedFileSystem is present in the list for HDFS and org.apache.hadoop.fs.LocalFileSystem for local file scheme. Thank you for the added info. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. hadoop. So I set the following configuration, and it got resolved. Initialized HDFS Storage Location ( Or disable HDFS permissions dfs.permissions.enabled = false ) sudo -u hdfs /usr/hdp/current/hadoop-client/bin/hadoop fs -mkdir /project_name sudo -u hdfs /usr/hdp/current/hadoop-client/bin/hadoop fs -chown project_user:project_user I was facing the same issue while running Spark code from my IDE and accessing remote HDFS. That class seems to be deprecated though, in favor of org.apache.hadoop.fs.Hdfs. This error is few times occurred classpath to hadoop jars isn't correct. Improving the copy in the close modal and post notices - 2023 edition. Create a jar file and execute the jar using hadoop command. fs. My final working spark-submit command stands as follows: The maven-shade-plugin in my project pom.xml is as follows: Note: The excludes in the filter will enable to get rid of. 03-13-2018 Is "Dank Farrik" an exclamatory or a cuss word? Already on GitHub? jetbrains IntelliIdea, Yayayayyc: I have got through this problem after some detailed search and did different trial methods. Sign in Everything is correct in my code and pom.xml. skein version: 0.8.0. How to convince the FAA to cancel family member's medical certificate? Is RAM wiped before use in another LXC container? 1. io. 01-26-2016 I have the following error when I'm running my Storm Topology that contains an Hbase Bolt. How is cursor blinking implemented in GUI terminal emulators? How to debug "No File System for scheme: hdfs" exception in Java? With prdesse, how would I specify what role the subject is useful in? So it was thrown out. How is cursor blinking implemented in GUI terminal emulators? Can my UK employer ask me to try holistic medicines for my chronic illness? Why Is PNG file with Drop Shadow in Flutter Web App Grainy? For the lost souls discovering this answer for Apache spark. 03:28 PM. and I followed hadoop No FileSystem for scheme: file to add "fs.hdfs.impl" and "fs.file.impl" to the Spark configuration settings somnathchakrabarti about 7 years added hadoop-hdfs jars with the --jars option while spark-submitting but giving java.lang.ClassNotFoundException :
Hadoop MapReduce job starts but can not find Map class? Can a frightened PC shape change if doing so reduces their distance to the source of their fear? To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Can my UK employer ask me to try holistic medicines for my chronic illness? Especially META-INFO/services directory, file org.apache.hadoop.fs.FileSystem. Pyarrow for some reason sets the hadoop executable to $HADOOP_HOME/bin/hadoop on python/pyarrow/hdfs.py:L137. Basically you need to add hadoop-hdfs in your pom dependency. Should I (still) use UTC for all my servers? I found two solutions: (1) Editing the jar file manually: Open the jar file with WinRar (or similar tools). java -classpath com.kangna. java.io.IOException: No FileSystem for scheme : hdfs. In which case we will fall back on managing the assembly build. Check line org.apache.hadoop.hdfs.DistributedFileSystem is present in the list for HDFS and org.apache.hadoop.fs.LocalFileSystem for local file scheme. Thank you for the added info. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. hadoop. So I set the following configuration, and it got resolved. Initialized HDFS Storage Location ( Or disable HDFS permissions dfs.permissions.enabled = false ) sudo -u hdfs /usr/hdp/current/hadoop-client/bin/hadoop fs -mkdir /project_name sudo -u hdfs /usr/hdp/current/hadoop-client/bin/hadoop fs -chown project_user:project_user I was facing the same issue while running Spark code from my IDE and accessing remote HDFS. That class seems to be deprecated though, in favor of org.apache.hadoop.fs.Hdfs. This error is few times occurred classpath to hadoop jars isn't correct. Improving the copy in the close modal and post notices - 2023 edition. Create a jar file and execute the jar using hadoop command. fs. My final working spark-submit command stands as follows: The maven-shade-plugin in my project pom.xml is as follows: Note: The excludes in the filter will enable to get rid of. 03-13-2018 Is "Dank Farrik" an exclamatory or a cuss word? Already on GitHub? jetbrains IntelliIdea, Yayayayyc: I have got through this problem after some detailed search and did different trial methods. Sign in Everything is correct in my code and pom.xml. skein version: 0.8.0. How to convince the FAA to cancel family member's medical certificate? Is RAM wiped before use in another LXC container? 1. io. 01-26-2016 I have the following error when I'm running my Storm Topology that contains an Hbase Bolt. How is cursor blinking implemented in GUI terminal emulators? How to debug "No File System for scheme: hdfs" exception in Java? With prdesse, how would I specify what role the subject is useful in? So it was thrown out. How is cursor blinking implemented in GUI terminal emulators? Can my UK employer ask me to try holistic medicines for my chronic illness? Why Is PNG file with Drop Shadow in Flutter Web App Grainy? For the lost souls discovering this answer for Apache spark. 03:28 PM. and I followed hadoop No FileSystem for scheme: file to add "fs.hdfs.impl" and "fs.file.impl" to the Spark configuration settings somnathchakrabarti about 7 years added hadoop-hdfs jars with the --jars option while spark-submitting but giving java.lang.ClassNotFoundException :  Not the answer you're looking for? 2 Everything is correct in my code and pom.xml. HadoopHadoopjar [2] [3]. If configured version of hadoop is 2.8.1, but in pom.xml file, dependancies has version 2.7.1, then change that to 2.8.1) By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. Making statements based on opinion; back them up with references or personal experience. Create Analytics from http using spark streaming, Failed to Save to S3 with error "java.io.IOException: No FileSystem for scheme: s3a". If this is the case, you have to override referred resource during the build. The following command 'unset HADOOP_HDFS_HOME'did the trick! in sbt we could do a mergeStrategy of concat or even filterDistinctLines. The solution is to display and set this class when setting Hadoop configuration: org. Thanks for contributing an answer to Stack Overflow!
Not the answer you're looking for? 2 Everything is correct in my code and pom.xml. HadoopHadoopjar [2] [3]. If configured version of hadoop is 2.8.1, but in pom.xml file, dependancies has version 2.7.1, then change that to 2.8.1) By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. Making statements based on opinion; back them up with references or personal experience. Create Analytics from http using spark streaming, Failed to Save to S3 with error "java.io.IOException: No FileSystem for scheme: s3a". If this is the case, you have to override referred resource during the build. The following command 'unset HADOOP_HDFS_HOME'did the trick! in sbt we could do a mergeStrategy of concat or even filterDistinctLines. The solution is to display and set this class when setting Hadoop configuration: org. Thanks for contributing an answer to Stack Overflow!  Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. java.io.IOException: No FileSystem for scheme : hdfs. I use sbt assembly to package my project. Is there an explicit classpath file that I should see or are you referring to theSPARK_DIST_CLASSPATH variable that is set in spark-env.sh? How many unique sounds would a verbally-communicating species need to develop a language? Connect and share knowledge within a single location that is structured and easy to search. Java HDFSjar:java -jar xxx.jar, HadoopHadoopjar[2][3], Hadoopfs.hdfs.implNo FileSystem for scheme, 1. java.io.IOException: No FileSystem for scheme: hdfs How to copy file from HDFS to the local file system, hadoop copy a local file system folder to HDFS, Exceptions in accessing HDFS file system in Java, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. Should Philippians 2:6 say "in the form of God" or "in the form of a god"? No FileSystem for scheme: hdfs No FileSystem for scheme: hdfs Labels: Apache Hadoop Apache HBase Gateway HDFS Conor New Contributor Created on 01-26-2016 06:10 AM - edited 09-16-2022 03:00 AM I'm getting this exception when trying to start my HBase master: Here is the output of hadoop classpath: Can I disengage and reengage in a surprise combat situation to retry for a better Initiative? By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. I am using Cloudera Quickstart VM CDH5.3.0 (in terms of parcels bundle) and Spark 1.2.0 with $SPARK_HOME=/opt/cloudera/parcels/CDH-5.3.0-1.cdh5.3.0.p0.30/lib/spark and submitting Spark application using the command, ./bin/spark-submit --class
Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. java.io.IOException: No FileSystem for scheme : hdfs. I use sbt assembly to package my project. Is there an explicit classpath file that I should see or are you referring to theSPARK_DIST_CLASSPATH variable that is set in spark-env.sh? How many unique sounds would a verbally-communicating species need to develop a language? Connect and share knowledge within a single location that is structured and easy to search. Java HDFSjar:java -jar xxx.jar, HadoopHadoopjar[2][3], Hadoopfs.hdfs.implNo FileSystem for scheme, 1. java.io.IOException: No FileSystem for scheme: hdfs How to copy file from HDFS to the local file system, hadoop copy a local file system folder to HDFS, Exceptions in accessing HDFS file system in Java, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. Should Philippians 2:6 say "in the form of God" or "in the form of a god"? No FileSystem for scheme: hdfs No FileSystem for scheme: hdfs Labels: Apache Hadoop Apache HBase Gateway HDFS Conor New Contributor Created on 01-26-2016 06:10 AM - edited 09-16-2022 03:00 AM I'm getting this exception when trying to start my HBase master: Here is the output of hadoop classpath: Can I disengage and reengage in a surprise combat situation to retry for a better Initiative? By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. I am using Cloudera Quickstart VM CDH5.3.0 (in terms of parcels bundle) and Spark 1.2.0 with $SPARK_HOME=/opt/cloudera/parcels/CDH-5.3.0-1.cdh5.3.0.p0.30/lib/spark and submitting Spark application using the command, ./bin/spark-submit --class